
Visualizing Locke and Mill
A {tidytext} analysis of John Locke and John Stuart Mill
Introduction
In this post, I will perform a text mining analysis of two important philosophical works on the topic of individual liberty: John Locke’s Second Treatise of Governement and John Stuart Mill’s On Liberty.
I will rely mainly on the tidytext package, as described in the book Text Mining with R: A Tidy Approach written by Julia Silge and David Robinson. My focus will be on comparing word frequencies to understand the degree to which word usage correlates between Locke and Mill.
A brief excursion into political philosophy
Second Treatise of Government was published in 1690, while On Liberty was published 1859. Both of these highly influential works are ostensibly about individual freedom. However, they are nonetheless different in important ways.
First, while Second Treatise is predominantly about civil liberty, or freedom from tyrannical forms of government that infringe upon individual rights to life, liberty, and property, On Liberty mainly focuses on personal liberty, i.e., freedom of speech/thought and social non-conformity.
Second, the two authors differed fundamentally in their view of natural rights (the background research for this section is based on Modules 2 and 8 from the Cato Institute’s Home Study Course). Locke argued that natural law gives all people universal and unalienable rights of self-ownership and self-determination, and that the purpose of government is to protect these rights. Mill on the other hand, being a disciple of Jeremy Bentham, did not believe in the logical existence of natural rights, and therefore made his defense of individual liberty from the standpoint of utilitarianism, or the greatest happiness for the greatest number.
Based on these differences, you might expect word usage to differ somewhat between Second Treatise and On Liberty. Let’s use R to take a look!
Tidytext in action
Project Gutenberg has both Second Treatise of Government and On Liberty in its free digital archives. I used the gutenbergr package developed by David Robinson to download the works.
# Load packages
library(gutenbergr)
library(tidyverse)
library(tidytext)
First, I used the metadata file from the gutenbergr package to find the
ID numbers for Second Treatise and On Liberty. Once I had these, I
was able to download each work using the gutenberg_download()
function.
Let’s start with Locke.
# Download Second Treatise of Governement
locke <- gutenberg_download(gutenberg_id = 7370)
# Show a selection of text
locke %>%
select(text) %>%
slice(50:56)
## # A tibble: 7 x 1
## text
## <chr>
## 1 Reader, thou hast here the beginning and end of a discourse concerning
## 2 government; what fate has otherwise disposed of the papers that should
## 3 have filled up the middle, and were more than all the rest, it is not
## 4 worth while to tell thee. These, which remain, I hope are sufficient to
## 5 establish the throne of our great restorer, our present King William; to
## 6 make good his title, in the consent of the people, which being the only
## 7 one of all lawful governments, he has more fully and clearly, than any
After we tidy it up with the tidytext package, it looks like this.
# Tokenize text and remove stop words
tidy_locke <- locke %>%
unnest_tokens(output = word, input = text, token = "words") %>%
anti_join(stop_words) %>%
mutate(word = str_extract(word, "[a-z']+"))
# Show a selection of tokens (words)
tidy_locke %>%
select(word) %>%
slice(144:170)
## # A tibble: 27 x 1
## word
## <chr>
## 1 reader
## 2 thou
## 3 hast
## 4 beginning
## 5 discourse
## 6 government
## 7 fate
## 8 disposed
## 9 papers
## 10 filled
## # … with 17 more rows
As you can see, the sentences have been broken up, or tokenized, into seperate words, and the stop words (here, the, and, etc.) have been removed.
A few notes about the code in the chunk above:
- While I chose to tokenize the text by word, there are many other
options in the
tidytext::unnest_tokens()function, including characters, sentences, and paragraphs. - Also, I used the
stringr::str_extract()function (as suggested in Text Mining with R) to change the output ofunnest_tokens()to include only actual words, and no numbers. Because, counterintuitively,token = "words"can also return numbers.
Next, I’ll do the same thing for On Liberty.
# Download On Liberty
mill <- gutenberg_download(gutenberg_id = 34901)
# Tokenize text and remove stop words
tidy_mill <- mill %>%
unnest_tokens(output = word, input = text, token = "words") %>%
anti_join(stop_words) %>%
mutate(word = str_extract(word, "[a-z']+"))
Now that we have two tidy data frames of words from each text, we can make some charts of word frequency to see how different Locke and Mill were with regard to word choice.
Visualizing word frequencies
Figure 1 plots the top 10 most frequently used words by John Locke in Second Treatise.
# Calculate word counts and percentages
tidy_locke_n <- tidy_locke %>%
count(word, sort = TRUE)%>%
mutate(pct = n/sum(n))
# Plot word frequencies
tidy_locke_n %>%
top_n(10, n) %>%
filter(word != "NA") %>%
ggplot(aes(x = reorder(word, n), y = n)) +
geom_col(aes(fill = pct*100)) +
coord_flip() +
labs(title = "Top 10 Most Frequently Used Words",
subtitle = "Second Treatise of Government, John Locke",
x = "",
y = "Frequency",
caption = "seth-dobson.github.io") +
theme(plot.caption = element_text(face = "italic")) +
scale_fill_continuous("% of Total")
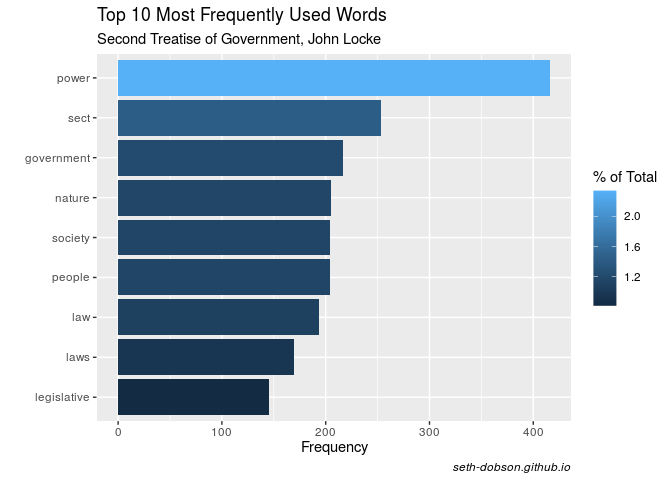
Fig. 1
By far the most frequently used word is “power”, which represents ~2% of all words. Other words in the top 10 reflect Locke’s focus on the proper role of government in people’s lives and his emphasis on natural law.
Figure 2 shows the top 10 most frequently used words in John Stuart Mill’s On Liberty.
# Calculate word counts and percentages
tidy_mill_n <- tidy_mill %>%
count(word, sort = TRUE)%>%
mutate(pct = n/sum(n))
# Plot word frequencies
tidy_mill_n %>%
top_n(10, n) %>%
filter(word != "NA") %>%
ggplot(aes(x = reorder(word, n),y = n)) +
geom_col(aes(fill = pct*100)) +
coord_flip() +
labs(title = "Top 10 Most Frequently Used Words",
subtitle = "On Liberty, John Stuart Mill",
x = "",
y = "Frequency",
caption = "seth-dobson.github.io") +
theme(plot.caption = element_text(face = "italic")) +
scale_fill_continuous("% of Total")
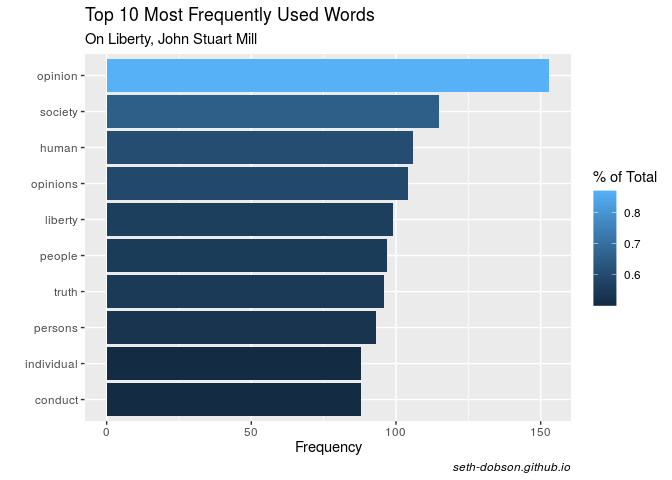
Fig. 2
“Opinion” is by far the most frequently used word. Together with “opinions”, these two words represent 1.46% of all words used by Mill.
# Calculate the summed percentage of "opinion" and "opinions"
tidy_mill_n %>%
filter(word %in% c("opinion", "opinions")) %>%
summarise(sum_pct = sum(pct)*100)
## # A tibble: 1 x 1
## sum_pct
## <dbl>
## 1 1.46
It is interesting to note that there is almost no overlap between the top 10 most frequently used words by Locke and Mill. Only the word “people” appears in the top 10 of both books.
If we combine both data sets into one data frame, we can look at the correlation between the frequencies for all the words. To do this, we need to join the word frequencies from Second Treatise with On Liberty.
Note, it’s important to use the dplyr::full_join() function here so
that we can get the full set of words across both books. The trick is to
then use dplyr::replace_na() to make all missing words have a value of
0.
Figure 3 plots the relationship between word frequencies for both books.
# Combine word frequency data frames
tidy_both_n <- tidy_locke_n %>%
select(word, n, pct) %>%
rename(n_locke = n, pct_locke = pct) %>%
full_join(y = tidy_mill_n, by = "word") %>%
rename(pct_mill = pct, n_mill = n) %>%
replace_na(list(n_locke = 0, pct_locke = 0, pct_mill = 0, n_mill = 0))
# Plot combined frequencies for all words
tidy_both_n %>%
filter(word != "NA") %>%
ggplot(aes(x = pct_locke, y = pct_mill, label = word)) +
geom_abline(intercept = 0, slope = 1, lty = 2, lwd = 1.05) +
stat_smooth(method = lm) +
geom_jitter(alpha = 0.25, size = 2.5) +
geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5) +
scale_x_continuous(labels = scales::percent_format(accuracy = .05)) +
scale_y_continuous(labels = scales::percent_format(accuracy = .05)) +
labs(title = "Comparison of Word Frequencies",
subtitle = "John Locke vs John Stuart Mill",
x = "Second Treatise of Goverment",
y = "On Liberty",
caption = "seth-dobson-github.io") +
theme(plot.caption = element_text(face = "italic"))
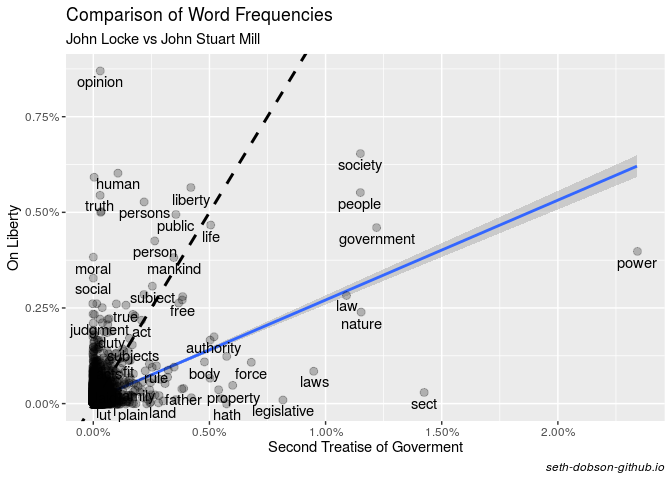
Fig. 3
As you can see, there is a positive correlation between the word frequencies overall, as indicated by the linear regression line having a slope > 0 (Pearson’s r = 0.448).
However, if we look at the dashed line in Figure 3, which is the line of identity (equal percentages), we see that that many of the most frequently used words in each book fall far from the line.
Nonetheless, there is a small set of words that each author uses relatively frequently that also show similar percentages. This set includes the words “liberty”, “life”, “public”, “person”, “mankind” and “free”.
Conclusion
Hopefully you will agree after reading this post that the tidytext package provides a relatively hassle-free way to get started quickly with text mining in R. My comparison of word frequencies between John Locke’s Second Treatise of Government and John Stuart Mill’s On Liberty only scratches the surface of what is possible with tidytext.
In future posts, I hope to go deeper with tidytext. But for now, thanks for reading!
Questions or comments?
Feel free to reach out to me at any of social links below.
For more R content, please visit R-bloggers and RWeekly.org.